
5 Claude Code Hacks That Helped us Win 🥈 at a Hackathon
How we used Claude Code as a system - not a chatbot - to trade tokens for outcomes 🧠

Recently our Torq team took 2nd place at a cyber hackathon.
Not because we wrote more code.
But because we changed how we worked with Claude Code.
We had six hours. Roughly 100k Sysmon events. And a scoring rule that punished token waste.
Some teams went deep on model and pipeline optimization.
We went in a different direction.
We treated Claude like a system - a team we could conduct.
That shift let us trade tokens for outcomes on purpose:
more findings with roughly the same token budget
or the same findings with far fewer tokens
And we shipped in time.

The 5 hacks (TL;DR)
Ultrathink - force real trade-off reasoning before you commit to an architecture.
feature-dev - multi-agent planning that explores your codebase before it codes.
Feedback loops - measure every iteration instead of trusting vibes.
Parallel Claude instances - split work across terminals like a human team.
AGENTS.md / CLAUDE.md - bake constraints into every session automatically.
Let me unpack each.
Hack #1: Ultrathink mode for architecture decisions
Most people skip this. We didn’t - because we knew our real bottleneck wasn’t coding, it was choosing the right architecture under a hard token constraint.
What’s not obvious (and barely documented) is that Claude Code maps specific phrases to increasing levels of internal thinking budget:
“think” < “think hard” < “think harder” < “ultrathink”
Each step explicitly allocates more reasoning time before Claude responds. ultrathink is the highest tier - it tells the system to slow down and spend real compute on trade-offs instead of jumping to an answer.
In practice, ultrathink makes Claude spend ~30–60 seconds actually reasoning before responding. Not just generating text, but weighing options, constraints, and second-order effects.
Without ultrathink: You get generic advice. “Use ML.” “Batch it.” “Try caching.”
With ultrathink: You get a real architectural breakdown:
2–3 plausible approaches
trade-offs
token cost estimates
implementation plan
Pay ~2k tokens for planning. Save ~80k tokens by not guessing. And yes I know it feels voodoo, but hey it works like hell!
When we use it:
architecture decisions (basically always)
algorithm design
perf/token optimization
when I feel “slightly unsure but already coding”
When we don’t:
tiny bug fixes
“add a button”
when I already know exactly what I want
Hack #2: feature-dev = multi-agent planning system
Everyone uses Claude Code to generate code. feature-dev is different: it’s really a planning orchestra.
We use it whenever we don’t trust our own context yet. Under hackathon pressure, that’s basically always.
What actually happens
Phase 1–2: Discovery + Exploration
Claude launches 2–3 explorer agents in parallel:
find similar features
map architecture + abstractions
spot existing patterns Then it reads the key files they found.
Phase 3: Clarifying questions (critical)
It asks about edge cases, integration points, perf requirements - and waits. No “AI guessing what I meant.”
Phase 4: Architecture options
You get 2–3 designs:
minimal change
clean separation
pragmatic middle ground with concrete trade-offs for your codebase.
Phase 5–7: Implement → Review → Summary
Only after you approve the plan.
Example:
/plugin marketplace add anthropics/claude-code
/plugin install feature-dev@claude-code-plugins
-- reset claude
/feature-dev:feature-dev Add network analysis hunterIt comes back with:
“here are the key files”
“here are 3 ways to implement it”
“pick one and I’ll code it”
That saved us from:
duplicating existing code
choosing the wrong abstraction
missing edge cases
Mini takeaway: If a feature touches more than ~2 files, let feature-dev plan it first.
Hack #3: Build your own feedback loop
Ok, this is actually were I need you to focus…
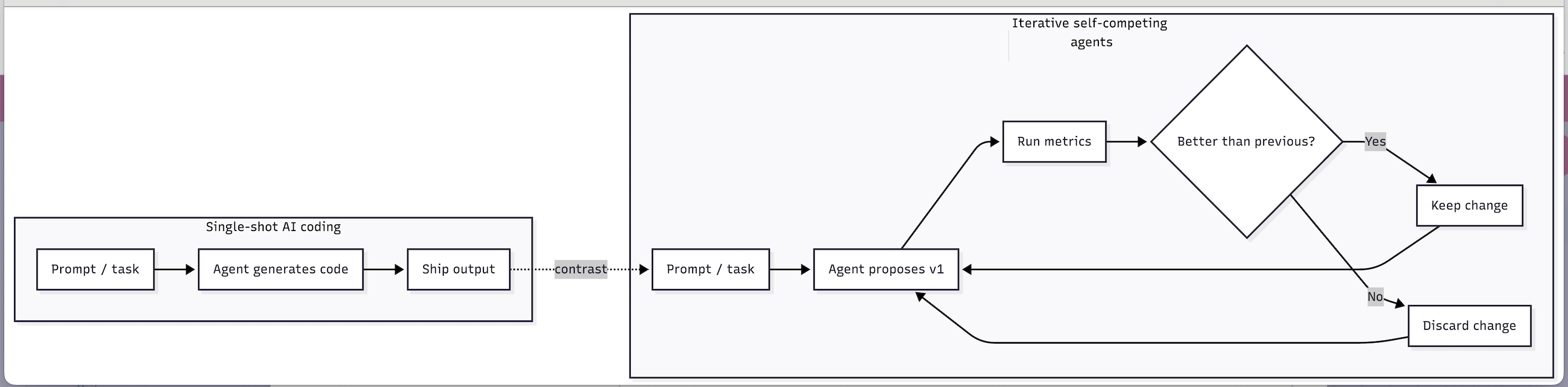
Here’s the default AI-coding loop most of us fall into:
Ask Claude to build something
Run it
Squint at the output
Repeat 🙃
Once Claude started producing options fast, we needed a way to stop arguing with vibes - so we forced ourselves into a data loop.
What we asked Claude to build
Two tiny scripts Claude generated for me as part of the workflow:
analyze_tokens.py- per-component token breakdowncompare_approaches.py- side-by-side comparison on quality + efficiency
Template you can steal:
# compare_approaches.py
def compare_versions(v1_id, v2_id):
“”“Compare quality + efficiency metrics.”“”
return {
“token_savings”: calculate_token_diff(v1_id, v2_id),
“quality_delta”: compare_outputs(v1_id, v2_id),
“false_positives”: count_fps(v1_id, v2_id),
}
Run:
python compare_approaches.py v1 v2Hackathon example outcomes:
v2 vs v1:
+23 detections
+12k tokens
→ NO (efficiency mattered)v3 vs v1:
+28 detections
–87k tokens
→ YES (ship it)
How I actually used the loop
The key wasn’t just writing scripts - it was how we ran Claude against them.
For each hunter/agent, we let Claude iterate on the implementation until the metrics got better than the previous version. If an iteration didn’t improve results after a few tries, I ditched that addition and moved on.
So the cycle looked like this:

Each agent kept looping until the numbers stopped improving. If it didn’t converge after a few iterations, we dropped it and moved on.
Generalize this:
building an API? measure latency + errors
refactoring? track bundle size + tests
adding a feature? measure impact + complexity
Mini takeaway: Don’t accept the first draft. Make Claude compete with itself - and ship only what measurably improves the outcome.
Hack #4: Run multiple Claude instances in parallel
This felt like cheating the first time we tried it. 😄
If your architecture is modular, you can have multiple Claude sessions working at once, each on a separate component.
During the hackathon I opened 3 terminals and gave each Claude instance a different hunter.
Rule we used: Each Claude session owns a file/folder. If two sessions touch the same file, you lose the speedup to merge drama. 📁
Result: what would’ve been ~30 minutes of sequential additions became ~10 minutes in parallel (closer to ~15 once I included the orchestration + feedback overhead).
How to set it up:
design modular pieces first (ultrathink helps)
identify truly independent components
open multiple terminals
run Claude Code separately in each
merge, test, compare, ship
Doesn’t work great for:
tightly coupled codebases
tiny tasks
when architecture is still fuzzy
Mini takeaway: Treat Claude like a team. Give each “teammate” a clean slice of ownership.
Hack #5: Strategic AGENTS.md (not just documentation)
We used to treat AGENTS.md like documentation. In this hackathon it became a constraint engine.
AGENTS.mdis not working by default with CC, we need to configure it with a rule or work directly with CLAUDE.md (but for working with other code agents - we need to AGENTS.md file
Our coding agents auto-load this file every session. So instead of re-prompting constraints 50 times, we wrote them once - and every parallel agent stayed aligned.
What we put in it
hard constraints (token budget, max tokens, scoring rules)
optimization rules of thumb
communication style
critical files: DO NOT TOUCH
Minimal skeleton:
# AGENTS.md
## Project Overview
AI security agent analyzing Sysmon logs (~100k events). Scores on token efficiency.
## Non-Negotiable Constraints
- 100k token max - fewer = higher score
- All LLM calls via TracedLLM wrapper
## Optimization Preferences
- Aggregate events before LLM calls
- Use structured output for parsing
- Keep prompts short - no redundant context
## Communication Style
- “Be extremely concise, sacrifice grammar for concision”
- Paragraphs → few words, headings, lists
## Plans
- End with unresolved questions (concise)
## Critical Files - DO NOT MODIFY
- `src/traced_llm.py` - token tracking (competition rules)Credit / inspiration: Some of the ideas around treating agents as first-class collaborators (and baking constraints into a shared context file) were inspired by short-form examples like this YouTube Short by Matt Pocock:
Mini takeaway: Set constraints once. Benefit everywhere.
The hackathon story (what we built, baseline vs our approach)
Task: Build an AI security agent that can process ~100k Windows Sysmon events and surface meaningful detections. Scoring rewarded detection quality/coverage and token efficiency, with a hard cap of 100k tokens per run.
Baseline approach
Classic single-agent pipeline:
preprocess logs
send large chunks to the LLM
generate detections/report
It worked… but cost ~103k tokens and missed coverage.
Our approach
Our Torq team created a multi-hunter architecture:
Preprocessing + metadata caching
5 parallel specialist hunters (fileless, sequence, process-tree, network, rare-event)
Merge findings + final report
Parallel specialists meant:
smaller, tighter prompts
less repeated context
better domain focus
much lower token burn
Diagram: baseline vs our approach

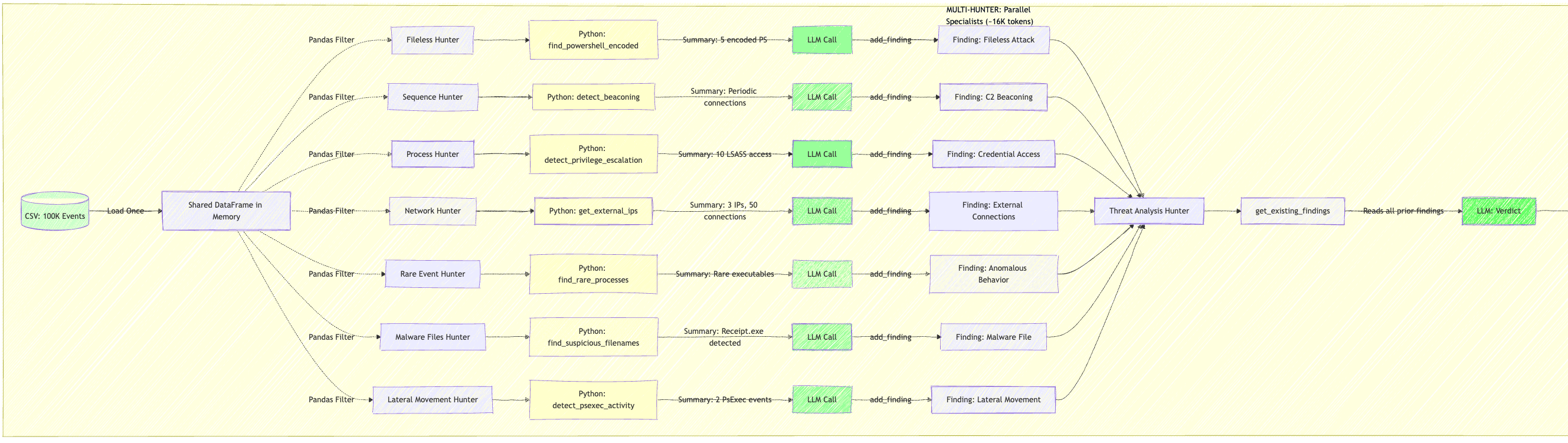
Results
Token efficiency
baseline: 103,419 tokens
our approach: 16,373 tokens
savings: 87,046 tokens (84%)
Quality
28 IOCs detected (vs 23 baseline)
12 MITRE techniques mapped (vs 8)
lower false positives
Time
full system built in ~6 hours
2nd place overall
want to see the full hackathon story? check out this link
The meta-lesson
We didn’t win by typing faster. We won by designing a workflow aligned with constraints:
Claude as a thinking partner (ultrathink)
planning before coding (feature-dev)
measuring instead of guessing (feedback loops)
parallelizing like a team (multi-instances)
baking constraints into context (AGENTS.md)
Hackathon meta: stop coding. start conducting.
Takeaways (what you should steal)
Start doing today
Add
ultrathinkbefore decisions that matterMeasure at least one real metric per iteration
Create a strategic
AGENTS.mdwith true constraints
Try this week 4. Use feature-dev for non-trivial changes
Try next big project 5. Design for parallel Claude sessions